Why Your Homelab Needs Backups Now: Lessons, Tools, and the 3-2-1 Rule

I have wasted more than 60 dollars because I left versioning on in my s3 bucket so the wrong thing that got backed up didn't get deleted fully and i was paying 7 dollars a day. You live and learn. But learn from my mistakes not yours
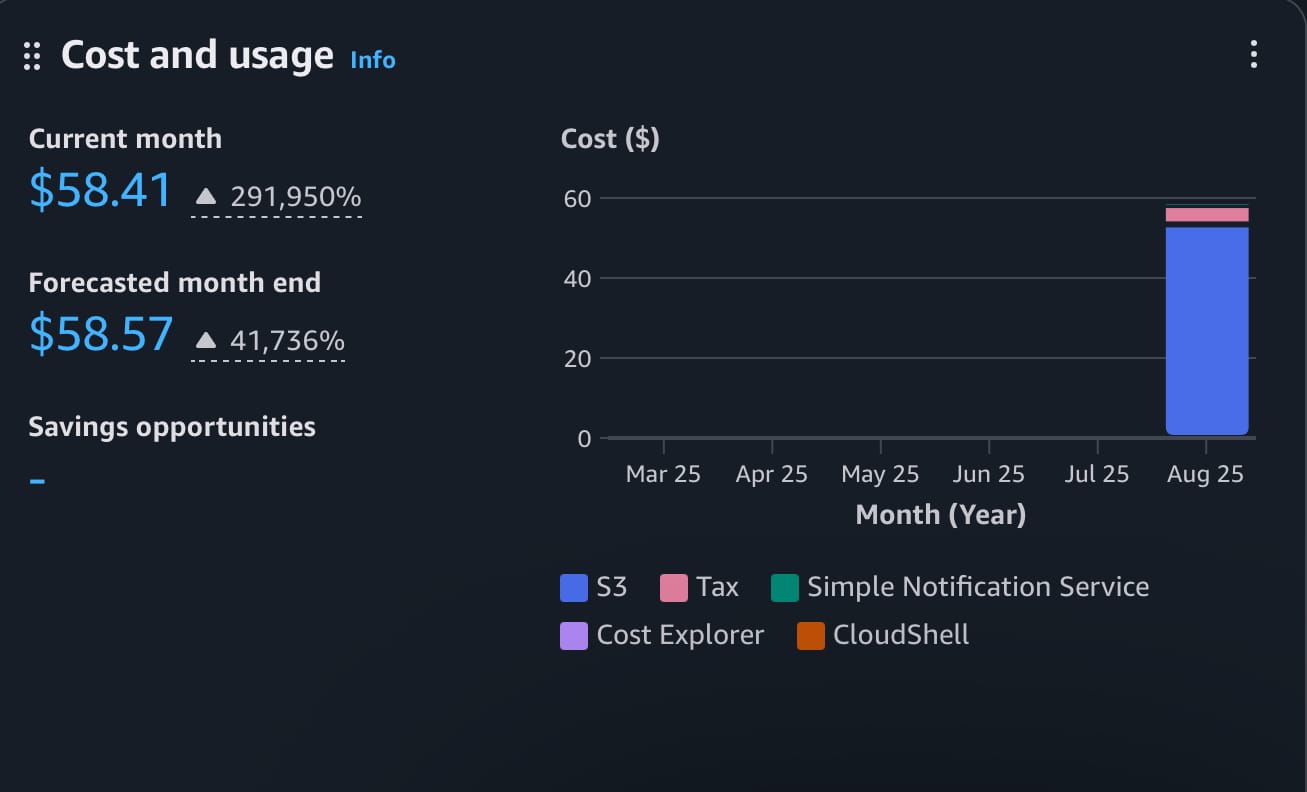
What i did wrong
I have been building my homelab since last year. I was running Proxmox but didn't have any backups, but that was okay because I wanted to move to Kubernetes, so i switched. I kept adding more services and things, and kept going still no backups for my Etcd. And then when I tried to install Cilium, and I messed up and bricked my DNS ( Its always DNS ). And I had to reinstall everything again ( Luckily my Persistent storage was still there so there was 0 data loss. )

You need to create backups first then build
I know this feels unneccessary, why would you create backup when you haven't built anything yet, you want to build something first then you will add backup later when big enough. Exactly what i thought before I broke my homelab and had to spend a month connecting back everything again and setting up all the configuration i had before.
Backups are an absolute necessity especially if you actually rely on your homelab more and more, if your services are important then having downtime is problematic, imagine switching from services like Google Drive or iCloud and you have been keeping your photos in your running Immich server, but you broke the server and can't backup photos anymore.
Maybe if this is just something for you, you could still bypass and deal with it in other ways, but what about the non-techy people or your family / friends. If they rely on it because this is something you wanted to push for, its affecting more than just you. Thats why people trust using those cloud services like Netflix or Google Drive.
The 3-2-1 Method

If you have researched backups at all this comes up quite often, if you haven't heard of this then this is one of the most solid methods for having backups, following this, you will never go wrong, but you should assume this is to be as safe as possible. You do not have to follow this and you can choose to do less if thats okay with you, remember you only need to do as much as you feel comfortable
3 Copies Of Data
This is so you have 3 copies of your data, 1 original, which is what you are using and 2 other copies in total. For me i don't have it "exactly" like that, I only have 2 actual copies but I count it as 3 because I have 1 copy that is saved on a system that has parity so I find it safe enough to be able to work for me,
2 Different Media Types
You want to have different types of media, HDD, SSD, thumbdrive, Cloud Storage, NAS, or even tape 😎 ( If you're old school ). Every type of media has a failure type and point, you have to choose what is best for you, I am running a NAS as my main and AWS S3 Cloud bucket as my backup. I know AWS services better so its easier for me to configure the backups, in a way I want.
1 Copy Offsite
You want to store this copy away from your house or building, this way you make sure in case of fire, earthquake, theft or anything you have this data somewhere where it wouldn't be affected, this is a method we commonly use in work when we are working on disaster recovery setups to make sure we keep data that needs to survive, survive.
Examples:
Based on how you want to setup your backup, I can give some examples for platforms that are very commonly used. If you aren't using these methods, I would suggest deeper research into what could be good ways to have backups, but for example Unraid and TrueNAS have built in plugins for uploading to s3 if that is what you are looking for
If you don't want s3, there are many services that provide s3 like data storage, you could be more familiar with Azure blob storage, Hetzner vault ( which is very similar to s3), and many other services like Oracle or Alibaba Cloud. The options are endless so no worries on what method you want to use, you will be able to find something, if not just msg me Gauransh Mathur on twitter, linkedin, and we can have a chat
Proxmox
For Proxmox you have a very easy and simple method of using Proxmox Backup Server (PBS) that is a seperate version for running backup for Proxmox. If you don't know what Proxmox is, you can read a bit more in Do You Need A Homelab? where I have discussed it a bit more.
PBS is simple to setup and has recently also got S3 native support at the time of writing this. There was a reason I didn't use it before but now it is also very useful for people like me. You can just run it as a VM in your Proxmox cluster.

This is a great tutorial if you want to setup PBS, I won't go into detail too much of how exactly to step by step install, but if it is content you would like to see, I will drop specific tutorials for Kubernetes Homelab specific posts.
Kubernetes
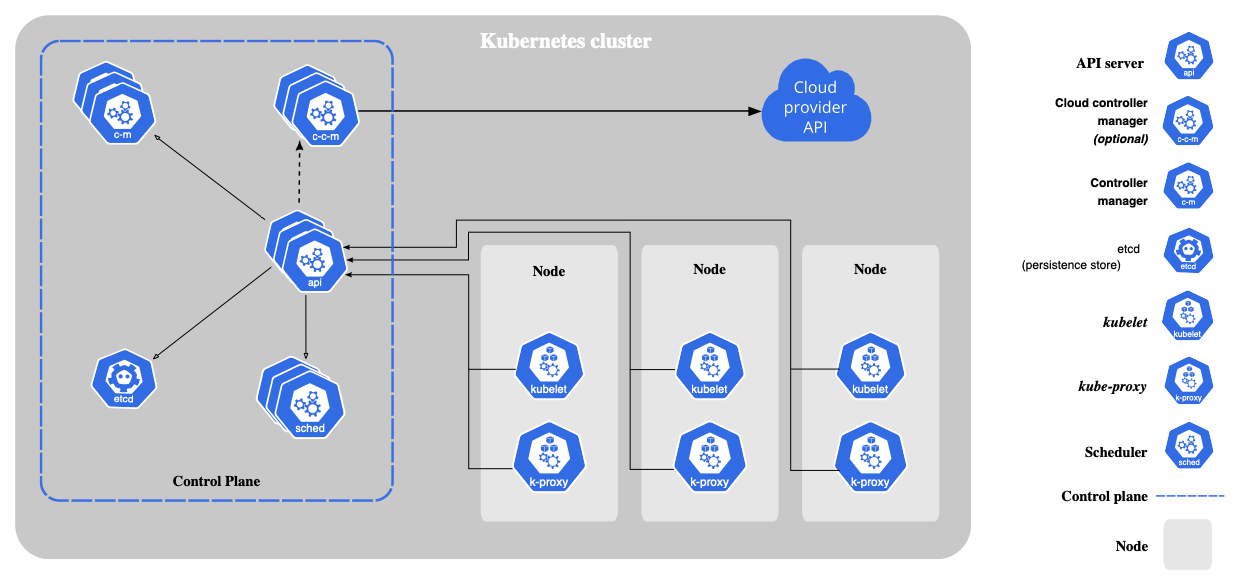
If you want to do backups for kubernetes there are so many ways, and no way is really wrong but i will explain my ways, and why I chose them. You won't exactly be able to follow all my methods and thats okay, I had to make certain choices on the basis of what felt worth spending money vs trying to FOSS it.
Sidero Omni talos ETCD backup:

I am running a SaaS called Omni, I will be releasing tutorials and things about this in more detail soon. But because I'm running kubernetes bare metal with the SaaS, I have it very simple to backup Etcd.
Etcd comes from /etc distributed, t's a distributed version of your system's config folder for large-scale setups. Thats why if you have many nodes, all the configuration is in the Etcd. Its super important as for cluster state, configs, and metadata. If this confuses you with too much lingo don't worry. I will work on more tutorials to explain kubernetes and its parts.
Based on my omni configuration, all I had to do was create a role and user for omni to be able to send the data to my S3 bucket, and I scheduled a 24h job that will run to create backups. I have also made policies for the S3 bucket to be able to delete old backups after 7 days, that way i keep cost super low and only need to have specific backups. I will also probably in the future have a policy adding to convert a weekly backup into a long term storage for super super safety, but everything else is fine for now.
Velero

This is your main man right here, this is what i use to backup the actual deployments and everything else. Having to figure out how to backup the real data. And this gives you so many options and is so easy to setup.
You will just need to configure it initially with what setup you want to do and what you would want to run, like backing up snapshots, backing up everything. I would suggest do not do everything, thats where the mistakes start. You want to plan what you are doing, so look and see what exactly will you need to recover. You won't need to backup the system if you are already doing Etcd backup so you can remove certain namespaces
I just had to do the same thing with velero, that I did for Omni where I made a role and user for it to be able to access the other bucket, then what I did was to run the schedule at 2 am, this is so no backups occur when I'm working on the lab specifically.
I have yet to setup PVC (Persistent Volume Claim) as of backing up, but I will, I made mistakes while doing this and want to do it the right way first. Then my full system will be backed up with 7 days of readily available.
This was a long post, but its important that you have good information for backing up because its very important if you are running your machines and even more if you are working on someone else's. But this also teaches you how to cut cost and have the best methods for setting everything up that way you can use it for any other reason you like.

Member discussion